ANNOTOS
Annotationsverfahren für die Extraktion von technischen Fakten aus Fließtexten
Zielstellung des Projektes
Ziel des Projektes ANNOTOS war es, computerlinguistische Verfahren und Werkzeuge zur Analyse von Fließtexten zu entwickeln. Im Fokus standen Texte zur qualitativen Beurteilung technischer Systeme, wie sie aus Zuschriften, Kundenbeschwerden und Fehlerbeschreibungen gewonnen werden können. Der substantielle Gehalt dieser Texte sind die Informationen, die für das Wartungsmanagement, die Produktverbesserung und die Qualitätssicherung wertvoll sind.
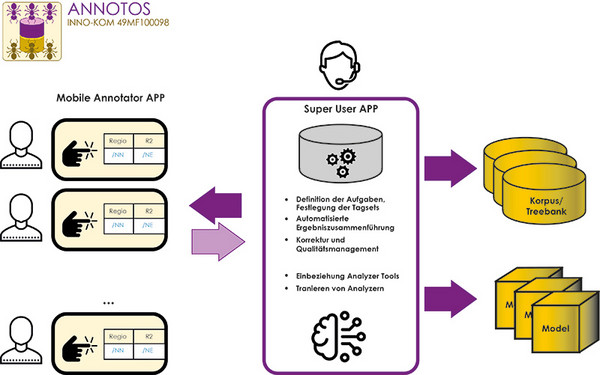
Im Projekt ANNOTOS wurden Methoden des Natural Language Processing (NLP) entwickelt, die die kollaborative Annotation anwendungsspezifischer Texte für den Aufbau qualitativ hochwertiger Fachkorpora unterstützen. Dazu gehören Verfahren der NLP-Pipeline (Part-of-Speech, Named Entity, Chunking, Dependency) und Verfahren zur Extraktion von eventbezogenen Aussagen. Das Gesamtverfahren umschließt neuartige Methoden zur interaktiven, schnellen und möglichst fehlerfreien Annotation an mobilen Clientrechnern und Verfahren für sogenannte Super User Arbeitsplätze, durch die die Einzelergebnisse automatisiert zusammenführt, kontrolliert und persistiert werden. Die zu benutzenden Tagsets sind frei konfigurierbar und werden vom Super User vorgegeben. Die Annotationsergebnisse werden in einer neuartigen Datenbasis gespeichert, aus welcher über verschiedene Protokollausgaben NLP-Trainingsmodule und Analyseverfahren gespeist werden können. Zum Anwendungsfall passende Analyseverfahren und Trainingsmodule wurden getestet, erweitert und in das Gesamtverfahren integriert.
Potentielle Anwendergruppen sind:
- Endanwender, die Texte erschließen (und evtl. mit Issue Tracking Systemen koppeln),
- Dienstleister, die Korpora für verschiedene Themenstellungen erzeugen und
- Software-Entwickler, die Parser herstellen oder verbessern wollen.
Nach Abschluss des Projektes wird damit begonnen, die FuE-Ergebnisse in marktreife Produkte zu überführen. Kooperationspartner sind willkommen.